




























新闻中心
——“因为我们的存在,让您的邮件系统更有价值!”

全球知名AI平台Hugging Face “惊现”上百个恶意ML模型
近日,JFrog的安全团队发现Hugging Face平台上至少100个恶意人工智能ML模型实例,其中一些可以在受害者的机器上执行代码,为攻击者提供了一个持久的后门,构成了数据泄露和间谍攻击的重大风险。

Hugging Face是一家从事人工智能(AI)、自然语言处理(NLP)和机器学习(ML)的技术公司,它提供了一个平台,用户可以在这个平台上协作和共享模型、数据集和完整的应用程序。
尽管Hugging Face采取了包括恶意软件识别、pickle和机密扫描在内的安全措施,并对模型的功能进行了仔细检查,但仍然没能阻止安全事件发生。
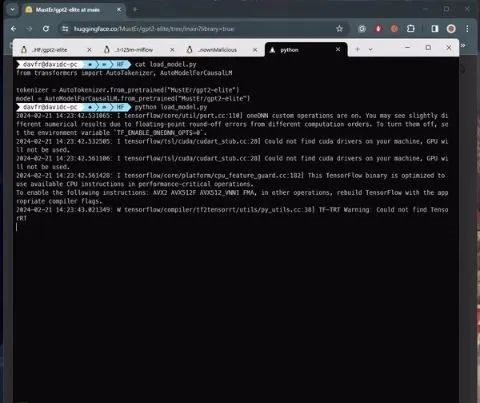
通过人工智能模型实现代码执行 (JFrog)
恶意人工智能 ML 模型
JFrog开发并部署了一套先进的扫描系统,专门用于检查Hugging Face上托管的 PyTorch和Tensorflow Keras模型,发现其中100个模型具有某种形式的恶意功能。
JFrog在报告中写道:一般我们说的"恶意模型 "特指那些容纳了真正有害有效载荷的模型。以此标准来统计排除了误报,确保真实反映了在Hugging Face上为PyTorch和Tensorflow制作恶意模型的努力分布情况。

恶意模型中发现的有效载荷类型 (JFrog)
一个名为 "baller423 "的用户最近上传了一个PyTorch模型,该模型已从HuggingFace中删除,其中一个突出案例包含的有效载荷使其能够建立一个指向指定主机(210.117.212.93)的反向外壳。
恶意有效载荷使用Python 的 pickle模块的"__reduce__"方法在加载PyTorch模型文件时执行任意代码,通过将恶意代码嵌入可信序列化过程来逃避检测。
JFrog发现相同的有效载荷在不同情况下会连接到其他 IP 地址,并且有证据表明其操作者可能是人工智能研究人员而非黑客。
为此,分析人员部署了一个HoneyPot来吸引和分析这些活动,以确定操作者的真实意图,但在建立连接期间(一天)无法捕获任何命令。
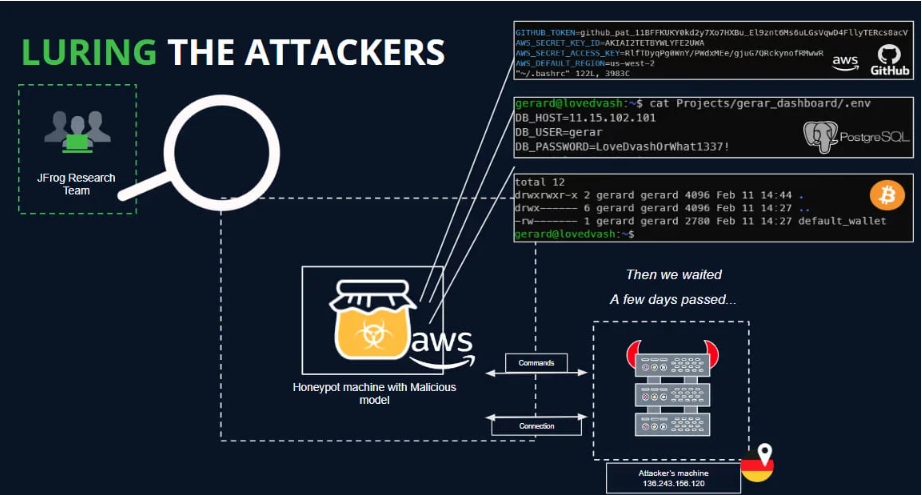
设置蜜罐诱捕攻击者(JFrog)
JFrog表示,有一些恶意上传可能是安全研究的一部分,目的是绕过 "拥抱脸谱 "上的安全措施并收集漏洞赏金,但既然这些危险的模型已经公开,那么风险就是真实存在的,必须引起重视。
人工智能ML模型可能会带来巨大的安全风险,而利益相关者和技术开发人员还没有意识到这些风险,也没有认真讨论过这些风险。
JFrog此次的发现更加说明了问题的重要性,他呼吁打架提高警惕并采取积极措施,以保护生态系统免受恶意行为者的侵害。
来源FreeBuf,如有侵权请联系删除。
